Examples
Document Q&A
Build RAG systems that answer questions from your knowledge base with cited sources.
This example demonstrates how to build a Retrieval-Augmented Generation (RAG) system that can answer questions from your documents with accurate, cited responses.
Example Workflow
Here's an example of a document Q&A workflow that retrieves relevant information and generates answers:
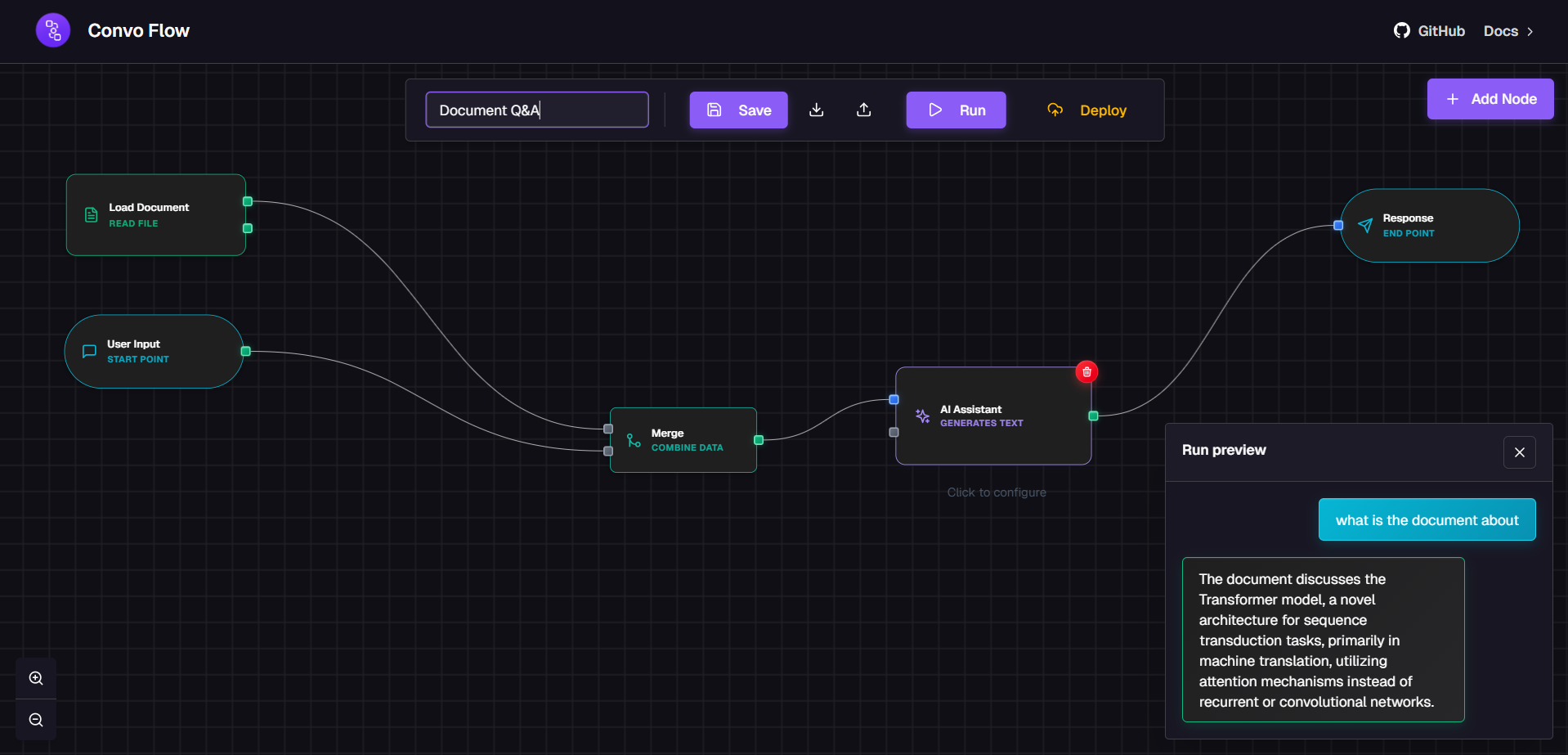
Key Features
- Document Loading: Load and process documents from various sources (PDFs, text files, etc.)
- Vector Search: Efficiently search through your document collection using semantic similarity
- Context Retrieval: Retrieve the most relevant document chunks for each query
- Source Citation: Provide citations and references to the source documents
- Accurate Answers: Generate answers based on your actual documents, not general knowledge
Workflow Components
- QueryNode: Captures user questions about your documents
- DocumentLoaderNode: Loads and processes documents (PDFs, text files, etc.)
- KnowledgeBaseRetrievalNode: Searches your vector database for relevant document chunks
- LanguageModelNode: Generates answers using the retrieved context and original query
- ResponseNode: Returns the answer along with source citations
Use Cases
- Answer questions from technical documentation
- Provide information from company policies and procedures
- Query research papers and academic documents
- Search through legal documents and contracts
- Answer questions from product manuals and guides
Configuration Tips
text
Document Loading:
- Support multiple file formats (PDF, TXT, DOCX, etc.)
- Configure chunking strategy (size, overlap)
- Set up metadata extraction
Vector Database:
- Connect to your vector store (Pinecone, Weaviate, etc.)
- Configure embedding model
- Set similarity search parameters
Retrieval Settings:
- Top K documents to retrieve
- Similarity threshold
- Re-ranking options
Response Generation:
- Include source citations in prompts
- Configure answer format
- Set context window limitsBest Practices
- Chunk documents appropriately (typically 500-1000 tokens)
- Include metadata (page numbers, document titles) for better citations
- Use appropriate embedding models for your domain
- Implement re-ranking for better retrieval quality
- Test with various query types to optimize retrieval parameters
Was this page helpful?